I recently had a chat with a friend of mine whose father was a farmer
back in the mid 20th century. In those days farmers had basically
two options when buying a tractor: Brand Green and Brand Red. My friend's dad
had been a die-hard Brand Green man for years. But one day his latest Green
tractor bit the dust and he went out and bought a Brand Red tractor. Surprised,
my friend asked his dad why he had switched brands after so many years. The
reply was, "too many parts." Apparently his dad had done some shopping this time
and discovered that Brand Red was building perfectly operable tractors with far
fewer parts to cause problems.
Such is the case in software. When I see a failed project I'm always looking
at something that has too many parts, most of which are completely unnecessary
replications and mutations of the same bad design. Adding to the problem
is the fact that access to these parts is generally far too wide-open - you can generally
manipulate most of the internal components of a failed software project even if you
have no business doing so. Imagine living in a house containing 10 or 20 times
as much stuff as you need, with essentially no walls so that all your neighbors
were free to reach in and diddle with all of your furniture as they please. What
kind of mess would you come home to every day? Such is the condition of today's
typical software project.
These next few articles on software deisgn are not just a bunch of academic
amusement - rather they discuss proven practices that will make a
difference of hundreds of thousands to millions of dollars in the cost of each
and every one of your enterprise software projects.
They are the essential components of software development success.
Our first remedy for managing the unfathomable complexity of large software
projects is called encapsulation. It's the most amazingly simple of all
the concepts we'll present, but despite that very few of the programmers
I've met in 35 years uses it.
Suppose that you are implementing a CRM system.that needs to store people's
addresses, among other things. Let's use the fairly traditional approach of
representing the address as a fixed set of fields like this:
- Street Address 1
- Street Address 2 (optional)
- City
- State
- Postal Code
- Country
So we have six fields representing an address. We have two basic options for
storing these fields:
- We can define them as just parts of a huge pile of other things we need
to store, such as people's names and personal data.
- Or we can encapsulate them, which means that we are going to
store them in a group that will contain only address fields.
Here are the two approaches side by side:
|
Huge Pile |
Encapsulation |
FirstName
Street Address 1
Street Address 2
Postal Code
LastName
Birthdate
Country
City
etc. etc.
|
|
Address Fields
|
Street Address 1
Street Address 2
City
State
Postal Code
Country
|
|
Personal Info
|
First Name
Last Name
Birthdate
|
|
Seems pretty trivial, no?
Actually it's not. I spent a lot more time formatting the right panel of
the above display, just as it takes more work for the programmer to encapsulate
fields. In programming parlance, each of the small "capsules" on the right side
of the table above is called a "class". It takes time to define classes, name
them, and organize fields into them than to simply make a huge intermixed list
containing all your fields. And by the way if you think the hodgepodge of
intermixed fields on the left is an exaggeration, think again. I see plenty of
code that looks like this almost every day.
But this is just the beginning, because even
if you "encapsulate" your fields into "classes", you have other, even more
time-consuming decisions to make. Those decisions involve how and who can access
those fields directly.
So how do we access these fields? One
very popular way is to simply make them all globally accessible, so that anybody
who can see the containing class can also modify its internal values. This is the lazy
approach and so it's also the most common approach and it's disastrous for many
reasons. Let us count the ways.
If all the code in the entire program can access the separate fields in our
Address Fields class, then we have very little control over what's in the class.
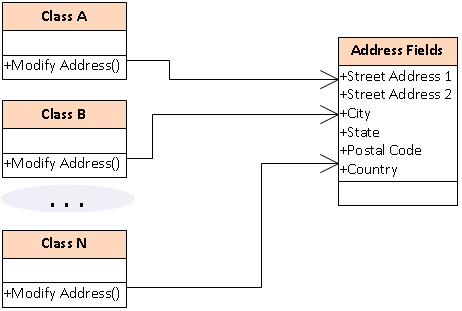
Notice that we have a bunch of external classes here (Class A, B, ... N), each of
which contains its own code that amodifies the address fields in our "Address
Fields" class. Each external class has its own "Modify" routine that may do
anything it wants to any or all of the publicly exposed fields in "Address
Fields". This makes for a very expensive maintanance process. In order to
maintain this program, a programmer must locate all the classes that might
access "Address Fields" and must further understand exactly how each of those
classes manipulates each of the fields. Often in a program like this, the
external classes have widely disparate and often conflicting ideas of what is
supposed to be in the fields. As a project ages, those disparities tend to
become wider and deeper.
But it's even worse than that. In a modern enterprise system we are likely to be
time-slicing the execution of the code in classes A, B, ... N. For example Class
A might write the first three fields and be put to sleep while Cass B takes over
and perhaps writes to all six fields. Later Class A wakes up and continues
writing the remaining three fields. Generally Classes A and B will be completely
oblivious to each other's existence, and we may end up with an inconsistent set
of data that neither Class A nor Class B intended to write. Time-slicing is also
unpredictable because it's not explicitly encoded: the operating system decides
how to time-slice such operations based upon its current convenience factors, so
the same code when run multiple times may be time-sliced differently, producing
constantly differing results that are mind-bogglingly expensive to debug.
Here's an analogy. Suppose we have an office with a single shared filing
cabinet. The above style of program design is akin to allowing direct access to
the filing cabinet by everyone in the office. Each person might have his/her own
filing style and may or may not know everything about how the office intends the
cabinet to be organized. In real life of course eventually the cabinet would be
full of filing errors and would probably be missing all or parts of some data
and might contain duplicates of other data. Imagine the expense of trying to
track down how the cabinet got into this condition and the further expense of
operational losses due to the disorganization of the cabinet and the loss of the
missing data.
A better solution would be to have only one person who is an expert in managing
the cabinet. Anyone withing to insert or retrieve files from the cabinet would
be required to go through this expert. Inappropriate requests would be filtered
out entirely. All others would be filed properly. At any given moment, such a
cabinet would be expected to be in good order. This is the concept of
encapsulated access. Here's the corresponding program design:
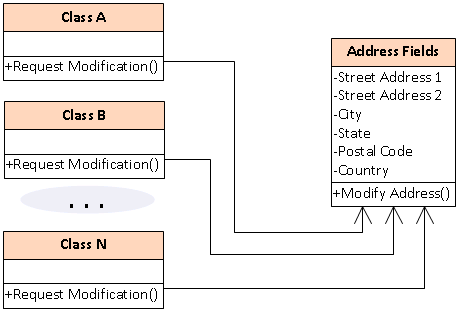
Note that the external classes no longer have the power to modify the
individual Address Fields; rather they may merely request that addresses be
modified. The Address Fields class itself now contains the one and only "Modify
Address" routine that embodies the complete and proper way to modify the address
fields. There are so many cost advantages to structuring a program this way that
I could not possibly list them all in a brief article, so I'll just hit the
major ones:
- A programmer can easily capture every attempt to modify the address
fields, since all requests go through the same place.
- Since all the requests can be captured in this one place, a programmer
can easily determine the sequence of requests that ultimately cause the data
to assume any given content.
- There is only one copy of the address-modifying code to maintain.
- Because there is only one copy, that copy is highly likely to embody
your company's correct procedure for modifying an address.
- Since the entire procedure is encoded in one place, it is possible for
your programmers to actually understand the procedure (conversely, snippets of
procedures distributed in time and space throughout an application are
almost impossible to analyze).
- Since it is far easier to maintain a single unified copy of the code
that performs a given function, it is also much easier to change that code
to meet changing requirements.
- Since it is easy for the programmer to conceive of the entire procedure,
it is also easy for the programmer to determine whether new requirements are
inherently incompatible with the existing requirements or with each other.
- A single, unified address modification routine can transactionalize the
writing of the fields, so that competing modification requests cannot
partially overlap each other and produce unpredictable partial results.
- If we want to add some new feature to the address-writing algorithm,
such as address verification with an external web service, there is only
one place in which to add it. Once we've added it there,
we know that the whole app is using the new feature consistently.
I could go on and on. What does this mean to you? Money, and plenty of it.
I've seen so many apps that were built without the use of encapsulation where
programmers must spend hours or even days figuring out the solutions to problems
that could have been fixed in minutes, or better yet may never have existed at
all with an encapsulated design. Can you afford to pay programmers a loaded
salary of $50 or $60 or $100 per hour to spend days tracking down a bug that
might never have existed had you designed your app using encapsulated classes?
How about dozens or hundreds or thousands of such bugs over the lifetime of an
app?
Encapsulation is fairly simple to implement but almost nobody uses it
because, like almost all good programming practice, it requires upfront
discipline, maturity, and a small investment. In my opinion the global payback on that
investment, were companies to make it, would surely be in the many billions of
dollars per year.
