:
Rapid Application Prototype
(or, hopefully, a revolution in software development)
Rapid Application Prototype (RAP) is a proprietary body of software produced by Project Pro, Inc., an Illinois software consulting company. RAP is both proprietary and copyrighted; nonetheless it is licensed (distributed) to the general public at no charge via Project Pro's web site. The purpose of RAP is to create a revolution in the way software is developed, thereby significantly reducing the cost of producing database-based applications such as interactive web sites and native database-based Microsoft Windows® applications.
Over the course of many decades there has been little efficiency improvement in software development . Computer hardware manufacturers have produced billion-to-one memory density improvements and million-to-one memory cost improvements over the course of the past forty years, but there has been no such overwhelming improvement in the field of software development, and in fact it could be argued that software development today is more expensive and risk-prone than ever.
Despite the appearance of various methodologies that supposedly improve software development efficiency (e.g. Waterfall, Agile, etc.) and despite the ever-increasing sophistication of software libraries and frameworks (e.g. .NET, J2EE), and despite the introduction of many new software tools, it still probably costs about the same and takes about as long to develop a software application as it did in 1970.
The computer hardware analogy serves to illustrate the relatively small effect of methodologies, libraries, and tools. In 1970 the current technology for manufacturing memory was the core plane, which at its apex achieved a density of perhaps a few bytes per cubic centimeter. Today's USB memory sticks have approximately a billion times that density. It would be utterly preposterous for anyone today to argue in favor of implementing memory using core planes. We can therefore deduce that something is significantly and indisputably better about today's silicon LSI implementations.
The very fact that software methodologies that were introduced decades ago are still in serious contention with more recently developed methodologies suggests that the value of methodologies themselves is in question. The Waterfall methodology was popular in 1970. It is still popular today. A number of other methodologies have come and gone and stayed in the intervening years, and the software community is divided into camps that argue over which one is best. A modern team of competent software developers could probably do approximately as well using either Waterfall (circa 1965) or Agile, which made its appearance in 2001. It would seem then that methodologies in general have little effect on software productivity. (This is not to say that they are worthless, but rather that productivity simply isn't affected much by them.)
Libraries and frameworks fare only somewhat better. By 1980 we had well-developed software libraries for performing all sorts of functions, including scientific calculations, networking, file system management, etc. In 2010 we have far larger libraries and in fact we could regard whole systems of web services as being "libraries". However software libraries are highly application-specific. True, you can probably write a program to perform Amazon transactions in one ten-thousandth of the time that it would have taken you to write an entire e-commerce application in 1970. Unfortunately (and unlike hardware), software has not evolved into a set of generic forms (akin to CPUs and memories) that function as universal engines for performing all sorts of tasks. A software library may dramatically improve a programmer's efficiency at doing one type of thing or even several specific types of things, but it has no implications for other types of things. In contrast, when you create a new technology for minimizing the size of transistors, you've improved the efficiency of essentially all digital hardware applications. So there is really no such thing as a library that makes the creation of essentially all software applications easier.
Finally we have tools. Here is an arguably complete list of tools that have created significant revolutions in software productivity:
Assembly language replaces machine language (late 1950s);
Compiled languages replace assembly language (late 1960s);
Compiled languages extended into object-oriented languages (early 1980s);
Graphic designers replace hand coding of user interfaces (1990s).
So tools have a considerably better track record than other software innovations - we can acknowledge their being responsible for at least four revolutionary increases in software productivity. The problem is that we don't seem to have a revolution in tools very often. The first three together are probably responsible for a million-to-one improvement in software productivity, but the last one of those happened thirty years ago, and a million-to-one is not even close to hardware's more recent billion-to-one improvement.
If hardware people managed their business the way that software people do, this year we’d probably be applying Agile development methodology using the latest wire-manufacturing technology in an effort to create the latest generation of core planes. We'd probably have tiny sub-assemblies (core-plane "libraries", if you will) by now, and a whole new generation of tools to pull tiny wires through doughnut-shaped magnets. And most of the electronic devices we take for granted today wouldn't exist.
When computer hardware takes a giant leap forward, it is not primarily via the employment of methodologies, libraries or new tools. Truly revolutionary hardware leaps occur when someone creates a profoundly new way of fabricating hardware, one that is demonstrably and unequivocally superior to the method that preceded it. Henry Ford, for example, did not reduce the cost of automobiles by reorganizing high-level worker behavior (methodology) or by merely consolidating parts into sub-assemblies (libraries). Nor did he revolutionize the auto industry by simple retooling.
Henry Ford revolutionized automobile production by fundamentally redesigning the way automobiles and their parts were created. This fundamental change then drove other changes in methodology, libraries, and tools. But these latter things were not the driving force.
Specifically, Ford did two things to make the process of automobile manufacture more efficient.
He adopted a hard design for the car and all of its components. Prior to Ford, cars were built by teams who created cars from the ground up, often using whatever materials happened to be available. The car's "design" was viewed to be a highly malleable thing, and consequently every instance of a given model might require significant rework. By specifying a hard design, Ford eliminated the need for on-the-fly rework and consequently eliminated the need for cars to be built by master craftsmen.
Ford eliminated useless variation in components. Previously, the components dictated the design; whatever components were available on a given day or chosen by a particular employee were incorporated. In Ford's new world, the design dictated that the components and assembly be as invariant as possible.
Note that Ford's prescriptive designs were not as restrictive as they sound. He did not dictate that all cars be the same forever (though he was fixated on producing only the Model-T for over a decade). His concepts were actually quite flexible in that they could be applied to many designs; as evidence we see that cars are still built today using his methods. His breakthrough was not in producing a particular design, but rather in dictating that there be an invariant design and that the entire production system would serve to implement that design faithfully.
If we are to similarly take giant leaps in software productivity, we will need to start creating software in a fundamentally different way. The "new way" will not be perfectly analogous to what hardware makers do, since software production is not strictly analogous to hardware production.
A software productivity revolution cannot be led by programmers. Programmers are paid for following established conventions and for producing expected results. Programmers have neither the incentive nor the authority to implement fundamental changes. Fundamental changes require relatively large investments of time and involve a fair amount of risk. As a programmer, I am not going to chance losing my job over the introduction of new technology that can't possibly work without the cooperation of my peers (over whom I have no control) and without the cooperation of my managers.
Similarly, a revolution in software productivity cannot be achieved by arms-length managers who involve themselves only in management of methodologies and schedules, or who manage primarily via the use of financial statements. A software revolution must be conducted by managers who are intimately involved in the software production process, to the point of fully understanding the programmers' code and coding processes. When an upstart company upends a whole industry, it is not because it has a CFO with an MBA at the helm (except perhaps in the finance industry). Upstarts in technology are generally headed by technologists.
You cannot lead programmers in doing profoundly new things unless you know precisely what it is they are going to do. Technology-heavy managers, therefore, must lead a revolution in software productivity.
The basis of Rapid Application Prototype (RAP) is similar to the basis of Henry Ford's revolution in auto production. There are two basic changes in the way software is produced:
RAP specifies a hard design for writing database-based applications. The design is both malleable enough that it can be applied to any such application (within reason). We no longer need master craftsmen and architects to create their own personal variations of the same thing; rather we choose one specific proven design and stick with it. In order to motivate programmers to use and abide by this hard design, we reward them by supplying code generators that create large portions of new applications automatically, freeing the programmer from the need to write them by hand.
RAP eliminates useless variation in components. Database tables are designed a certain way, without exception. So are primary and foreign keys. Every table maintains the same status fields in every record. Relationships between tables are specified a certain way. Business rules are built using only two basic patterns. User interfaces are built using a limited set of specific visual patterns. Wherever highly regular, detailed code is required, RAP generates it automatically rather than leaving it to the variable skills and tastes of the programmer.
In the process of radically simplifying the art of database-based application production, RAP creates apps with tangible business benefits that would be simply too expensive or would require too much implementation skill to be provided in typical, hand-crafted applications. These benefits are as follows:
RAP applications are 100% self auditing; i.e. all versions of all data in all tables is preserved, even after actually being deleted;
RAP automatically transactionalizes all database "write" operations, so that sets of records that are written together are always complete and have the same audit data, such that they can always be retrieved as a coherent group;
Because all data is audited and because all sets of records that were ever written by the application are stored coherently, it is possible for any application to go "back to the past" by specifying a given date on which all data is to be retrieved - hence auditing can be performed by simply opening a RAP application with a specified date;
RAP applications automatically perform concurrency management (i.e. two users cannot clobber each other's edits);
RAP applications never need to perform cascading updates, which enormously improves efficiency when writing to the database;
RAP applications automatically perform cascading deletions correctly and can implement far more options for conditional deletion than can any application that relies on database-based cascades;
RAP has a fully recursive naming mechanism for identifying records in the database, and consequently (with a little help from the developer) RAP applications can deliver error messages containing fully descriptive user-friendly names for objects in the database;
When produced by a reasonably skilled programmer who understands the model, RAP applications are incredibly reliable.
All of these are merely side benefits of using RAP. The primary benefit is that RAP dramatically improves your software development productivity. Because systematic design is so foreign to the mind of today's typical programmer and programming manager, it is hard to emphasize this concept enough.
Let's consider just one of these features, namely auditing. In a typical software project, auditing would, at most, be partially implemented for only certain tables. Such an implementation would require some specialized tool or interface in order to retrieve past versions of data. Implementation of auditing features would be left for last or perhaps abandoned entirely. In contrast, when people see (in demonstrations) that RAP creates a self-auditing application automatically and that this application requires no special tools or interfaces in order to view past data, they are so amazed that they tend to get the idea that RAP is all about auditing, or that they can somehow get this auditing feature without rebuilding their apps systematically. But automatic generation of 100% self-auditing applications is not the purpose of RAP; rather it is merely a byproduct of RAP's systematic design.
In the following sections we will dispense with the rationales for the various RAP conventions, preferring instead to simply state the conventions. Justifications for the use of these conventions would occupy an entire book, and so we leave them to some future document.
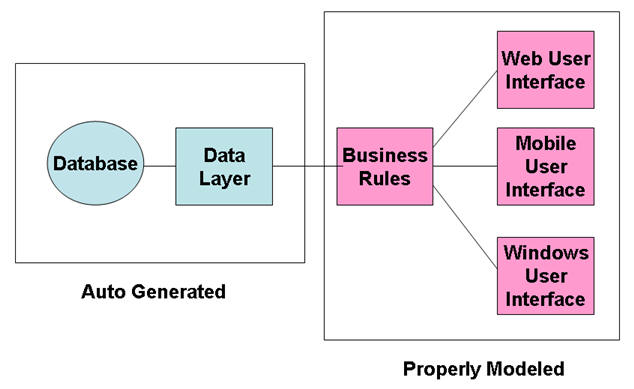
A traditional four-tier design model is used in RAP. Some people would not count the Database as a "tier" and so they would call it three-tier:
:
RAP saves development time and cost by generating almost all of the code in both the Database and the Data Layer. In the Business Rules and the User Interface, it imposes strict design rules that limit programmers in producing useless variations and coding errors.
RAP's name contains the word "prototype" because RAP comes with a complete example four-tier application that shows how a RAP application is constructed. Developers are encouraged to create new RAP-based applications by copying this example and changing the hand-generated portions. At this writing, this example is called ExampleCRM and it is only partially implemented (but the partial implementation is enough to show how RAP works).
RAP applications have a project structure that looks like this:
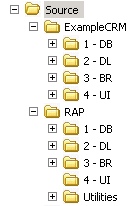
A RAP application (in this case ExampleCRM) is built parallel to the RAP system. The two have identical structures except that RAP has a "Utilities" folder. containing all the code-generating utilities that you would use to build the database and data layer of your own app.
ExampleCRM is a prototype. The way you develop a RAP application is to reconstruct your own version of "ExampleCRM" in a separate set of parallel folders, substituting your own schema in the database (DB) project, substituting RAP-generated code for the data layer (DL) project, and building your own business rules and UI using the ExampleCRM "BR" and "UI" projects as templates.
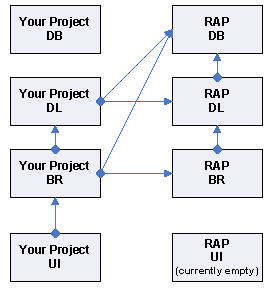
The following RAP folders contain compiled libraries that need to be included in your projects:
DB: contains a project called DBAccessLibrary that contains basic database access functionality.
DL: contains a project called DLMapper that contains the RAP ORM and other functionality that you must access.
BR: contains a project called BRBase that defines the basic entities used in your project's business rules.
Project dependencies among these projects are as follows:
To produce a RAP database, a programmer or database designer first designs a schema. RAP does not have the power to impose proper normalization rules upon the database designer, so at this point we are still relying on the designer to understand normalization and to design a properly normalized database. We recommend that the database be in at least a fourth normal form. Once a schema is designed, the programmer uses RAP utilities to create the tables and all the associated functions and stored procedures that the Data Layer uses to access the tables.
The RAP programmer defines tables by putting a series of table definitions into an SQL file. Here is an example of a single table definition
-- User
create table TBadmUser
(
--#include "PrimaryKey.sql"
-- indexed fields
LoginName DRLoginName,
constraint UK_TBadmUser_LoginName unique nonclustered (LoginName),
--#include "CommonFields.sql"
)
This is an extremely simple table that contains only one field in addition to the standard primary key and audit fields that adorn every RAP table. The "#include" directives are similar to C-preprocessor directives that cause the contents of the named file to be included in-line, allowing one copy of common code to be replicated perfectly (these are discussed in detail below).
RAP tables follow the following conventions:
In the example "TBadmUser" table above, the name has the following three sections:
RAP tables define their fields in the following order:
A more complex table definition that contains four of the five categories above is:
-- State/Province create table TBcrmStateProvince ( --#include "PrimaryKey.sql" -- foreign keys CountryId DRBigId, constraint FK_TBcrmStateProvince_Country foreign key (CountryId) references TBcrmCountry (CountryId), -- indexed fields Code DTStateCode, -- optional because provinces may not have codes constraint UK_TBcrmStateProvince_Code unique nonclustered (CountryId, Code), Name DRDescription, -- required constraint UK_TBcrmStateProvince_Name unique nonclustered (CountryId, Name), --#include "CommonFields.sql" )
By convention, RAP defines a set of SQL types that are used in the definitions of primary keys and audit fields. These data types may be used by developers in defining the developer-supplied fields of tables (as shown in these examples here). Such definitions can be found in a file called DataTypes.sql in the DDL section of the example RAP code. These data types follow this naming convention:
For a more complete example of the complete structure of a RAP source file that defines tables, see the example "Tables.sql" file that is provided with RAP.
RAP comes with a Database Preprocessor that substitutes the "#include" directives in the examples above with their corresponding file contents. The preprocessor performs the following macro-like substitutions within the text of the included files:
Instructions for running the preprocessor are included in the RAP demo package.
The two files "PrimaryKey.sql" and "CommonFields.sql" in the provided example code show examples of the use of these two substitutions. Here we show the output code generated by the definition of the small table "TBadmUser", whose source code was shown above:
-- User
create table TBadmUser
(
--#include "PrimaryKey.sql"
-- Primary Key
UserId DRBigId identity(1,1),
constraint PK_TBadmUser primary key clustered ( UserId asc ),
-- indexed fields
LoginName DRLoginName,
constraint UK_TBadmUser_LoginName unique nonclustered (LoginName),
--#include "CommonFields.sql"
-- Note Fields
Notes DTTextMax,
-- Audit Fields
AuditDate DRDateTime default current_timestamp,
AuditUserId DRBigId default 1,
constraint FK_TBadmUser_AUI foreign key (AuditUserId) references TBadmUser (UserId),
AuditStatus DRCodeSmall default 'I'
)
The black code in bold here was inserted by the preprocessor. (Unlike with the C preprocessor, the RAP preprocessor leaves #include directives in line with the code that they include.)
By requiring every table definition to contain directives that define the table's primary key and common fields (including audit fields), total consistency in primary key and common field definition is achieved, so that every RAP table has the same type of primary key and the same set of status fields.
The output of the preprocessor can be placed directly into an SQL Server query window and executed, producing the application's tables.
After you have created your database tables using the RAP preprocessor, there is an enormous amount of code that must then be generated using the RAP Database Generator. Instructions for running the Generator are included in the RAP demo package.
The Database Generator creates the following:
For each primary table whose definition was generated by the Preprocessor, the Generator creates one corresponding "archive" table. For example here is the archive table corresponding to TBadmUser above:
-- **** AUTO-GENERATED ARCHIVE TABLE FOR 'TBadmUser' ****
if not object_id('TBadmUser#', 'U') is null drop table TBadmUser#
GO
create table TBadmUser#
(
-- declare shadows for the current table's fields
UserId bigint,
LoginName varchar(20),
Notes varchar(max),
AuditDate datetime,
AuditUserId bigint,
AuditStatus char(1),
-- define primary key
constraint PK_TBadmUser# primary key clustered
(
AuditDate asc,
UserId asc
)
on [PRIMARY]
)
go
-- PRIMARY KEY INDEX SHADOW (NONUNIQUE)
create index ID_TBadmUser#
on TBadmUser#
(
UserId
)
-- ORDINARY INDEX SHADOW (NONUNIQUE)
create index UK_TBadmUser_LoginName#
on TBadmUser#
(
LoginName
)
The archive table is identical to the current-record table except:
The archive table keeps an active, retrievable history of all versions of all records that have ever existed in the corresponding primary table. The primary table's primary key is a synthetic key, which is guaranteed to be both unique and invariant for all time. Thus it is possible to find all the versions of a given primary-table record by looking in the archive table for all records having that same value in the field corresponding to the primary table's primary key..
The archive table tracks the changes to primary-table records via the use of two of the "audit" fields, which are always copies of the corresponding audit fields in the corresponding record in the primary table (until the corresponding primary-table record is deleted). These two audit fields are:
Except in the case of deletion (where the primary record no longer exists) the audit-table record is always a copy of the corresponding record in the primary table. In the case of deletion, the audit-table is identical to the deleted record at the time of deletion except that AuditDate contains the date/time at which the primary record was deleted and the AuditStatus contains "D".
Following is an illustration of how the fields of the archive table are generated when a given record in the primary table is modified. First, let's see a diagram of the correspondence between the primary and archive tables. Here is an illustration of a primary-table schema:
| <synthetic key> | ... | AuditDate | AuditUserId | AuditStatus |
| <integer> | ... | <date/time> | <foreign key> | <I/U/D> |
and below is an illustration of some sample contents of both the primary and archive tables, with the primary table's values in red and the archive table's values in green. The ellipsis represents the functional fields of the record (i.e. the fields that store data used by the application). Here we show what happens when we insert a record in the primary table:
| <synthetic key> | ... | AuditDate | AuditUserId | AuditStatus |
| 12345 | AAA | 9.1.08 15:30:10 | 375 | I |
| 12345 | AAA | 9.1.08 15:30:10 | 375 | I |
Note that the values in both records (red for the primary table and green for the archive) are identical. Now let's update the record in the primary table:
| <synthetic key> | ... | AuditDate | AuditUserId | AuditStatus |
| 12345 | BBB | 9.2.08 18:20:20 | 221 | U |
| 12345 | AAA | 9.1.08 15:30:10 | 375 | I |
| 12345 | BBB | 9.2.08 08:20:20 | 221 | U |
Note that the most recent archive record is identical to the current primary record. Also note that we are using arbitrary numbers for the AuditUserId foreign key, for the purpose of illustrating that the changes could be being performed by a number of different users. Now let's update the primary record again:
| <synthetic key> | ... | AuditDate | AuditUserId | AuditStatus |
| 12345 | CCC | 9.2.08 11:35:00 | 12 | U |
| 12345 | AAA | 9.1.08 15:30:10 | 375 | I |
| 12345 | BBB | 9.2.08 08:20:20 | 221 | U |
| 12345 | CCC | 9.2.08 11:35:00 | 12 | U |
Note that the most recent archive record is still identical to the current primary record. Now let's delete the primary record:
| <synthetic key> | ... | AuditDate | AuditUserId | AuditStatus |
| <primary table record deleted> | ||||
| 12345 | AAA | 9.1.08 15:30:10 | 375 | I |
| 12345 | BBB | 9.2.08 08:20:20 | 221 | U |
| 12345 | CCC | 9.2.08 11:35:00 | 12 | U |
| 12345 | CCC | 9.4.08 15:21:33 | 101 | D |
After a deletion, the record no longer exists in the primary table. Its memory is preserved, however, along with its AuditDate of deletion and its AuditStatus of "D" and the ID of the user who deleted it, in the archive table.
This example tracks the progress of auditing in just one table. All the tables in the database, without exception, operate on this same principle. Further, whenever a group of records in various tables is updated as a group, even through multiple operations (i.e. insertions, updates, deletions), all the records in that group are written with the same AuditDate. This means that when RAP retrieves records from the audit tables by date, the data is always delivered in self-consistent groups, i.e. you will not see child records pointing to nonexistent parents or sets of records containing possibly inconsistent collective data that they never actually contained when they were current.
Once we have created all the primary tables and audit tables, we need database code to coherently manage them. The RAP database generator creates a set of stored procedures that performs this function for each table.
Here is the Insert routine (the bold stuff is the core; everything else is provided just for context):
-- **** AUTO-GENERATED 'INSERT' STORED PROCEDURE FOR 'TBadmUser' ****
if not object_id('SPTBadmUser_Insert','P') is null drop procedure SPTBadmUser_Insert
go
create procedure SPTBadmUser_Insert
-- declare parameters for all fields except primary key & archive management
@LoginName varchar(20),
@Notes varchar(max),
@AuditUserId bigint,
@AuditDateNEW datetime
as
-- INITIALIZE
declare @ReturnValue int
select @ReturnValue = 0
declare @ErrorMessage varchar(max)
-- MAIN PROCEDURE BODY
begin try
-- declare & set the Archive-field-related 'parameters' that we didn't pass
declare
@AuditStatus char(1)
select @AuditStatus = 'I'
-- insert into the 'current' table and archive the record
insert into TBadmUser
(
LoginName,
Notes,
AuditDate,
AuditUserId,
AuditStatus
)
output inserted.* into TBadmUser#
values (
@LoginName,
@Notes,
@AuditDateNEW,
@AuditUserId,
@AuditStatus
)
-- get the key of the newly created record
declare @UserId bigint
select @UserId = scope_identity()
end try
begin catch
select @ErrorMessage = error_message()
select @ReturnValue = -1
end catch
-- TERMINATE
if @ReturnValue < 0
exec SPutlRaiseSystemError 'SPTBadmUser_Insert', 'Database Error', @ErrorMessage
-- Emit the record we just inserted and return the return value
select * from UFTBadmUser##PK(null, @UserId)
return @ReturnValue
As you can see, the insertion routine is very simple, and we've highlighted the core of it, which is a single INSERT statement with an OUTPUT clause. This statement inserts precisely the same record into both the original (i.e. current-data) table (in this case TBadmUser) and the archive table, as illustrated in the auditing discussion above.
The procedure is mostly quite straightforward and so we will explain only the few things of interest. First are the parameters:
@LoginName varchar(20), @Notes varchar(max), @AuditUserId bigint, @AuditDateNEW datetime
The LoginName parameter is the only true "payload" field in this table. Had there been ten user-specified fields in the table definition, there would be ten parameters in place of this one. Such values are of course simply inserted into the new record.
The Notes and AuditUserId fields are two of the standard fields appearing in every table. It is common for people to eventually want to be able to put notes alongside many things, and so for the purpose of illustration we made it a standard field, but RAP does not require its presence. To create a database that does not have a Notes field in every record, simply remove the Notes definition from RAP's list of standard fields (in CommonFields.sql)..
The application must supply the user ID (AuditUserId) of the user inserting the record.
Finally, the application must supply the AuditDate (i.e. the date/time of the record creation) for the new record. This warrants some explanation. First, we use the parameter name AuditDateNEW rather than just AuditDate because in the upcoming Update and Delete routines, the caller must pass in both the record's current AuditDate (for concurrency management) and a new AuditDate. The insertion of course does not require concurrency management, but for the sake of consistency we name this parameter AuditDateNEW, which is the name of the parameter serving the same purpose in the Update and Delete routines.
The reader may question why the application should pass the audit date at all; why not just have each insertion routine internally get the current date from the database and put that value in this field? The answer has to do with auditing. The reason we store the AuditDate at all is to retrieve historical data from the archive tables. If a set of records is being written (added, updated, deleted) as a group, then we need to be able to retrieve them as a group. In order to ensure that all records written together are also retrieved together, they must all have precisely the same AuditDate. Therefore we cannot leave it to the individual insertion routines (for each table) to each supply AuditDates on the fly. Instead, the application must generate a single date to be used on absolutely every record involved in a given transaction.
The update routine is similar to the insertion routine except that it updates an existing record.
-- **** AUTO-GENERATED 'UPDATE' STORED PROCEDURE FOR 'TBadmUser' ****
if not object_id('SPTBadmUser_Update','P') is null drop procedure SPTBadmUser_Update
go
create procedure SPTBadmUser_Update
-- declare parameters corresponding to current table fields, except audit status
-- NOTE: AuditDate must contain the original value from the fetch of this record
@UserId bigint,
@LoginName varchar(20),
@Notes varchar(max),
@AuditDate datetime,
@AuditUserId bigint,
@AuditDateNEW datetime
as
- INITIALIZE
declare @ReturnValue int
select @ReturnValue = 0
declare @ErrorMessage varchar(max)
-- MAIN PROCEDURE BODY
begin try
-- declare variables to hold values from all fields except primary key & audit status
declare
@_LoginName varchar(20),
@_Notes varchar(max),
@_AuditDate datetime,
@_AuditUserId bigint
-- assign field values from the record into these newly declared variables
select
@_LoginName = LoginName,
@_Notes = Notes,
@_AuditDate = AuditDate,
@_AuditUserId = AuditUserId
from TBadmUser
where
UserId = @UserId
-- see if this record has been deleted or modified since being acquired
exec SPutlCheckOptimisticConcurrency @_AuditDate, @AuditDate, 'SPTBadmUser_Update'
--test parameter values to see if any disagree with record values
declare @equal tinyint
select @equal = 1 -- assume all new values equal to old values
if @LoginName is null and @_LoginName is not null
or @LoginName is not null and @_LoginName is null
or @LoginName <> @_LoginName select @equal = 0
if @Notes is null and @_Notes is not null
or @Notes is not null and @_Notes is null
or @Notes <> @_Notes select @equal = 0
if @AuditUserId is null and @_AuditUserId is not null
or @AuditUserId is not null and @_AuditUserId is null
or @AuditUserId <> @_AuditUserId select @equal = 0
-- if anything was not equal, proceed with the audit and update
if @equal = 0
begin
-- set audit management values
declare
@AuditStatus char(1)
select @AuditStatus = 'U'
-- update and archive the record
update TBadmUser set
LoginName = @LoginName,
Notes = @Notes,
AuditDate = @AuditDateNEW,
AuditUserId = @AuditUserId,
AuditStatus = @AuditStatus
output inserted.* into TBadmUser#
where
UserId = @UserId
end
end try
begin catch
select @ErrorMessage = error_message()
select @ReturnValue = -1
end catch
-- TERMINATE
if @ReturnValue < 0
exec SPutlRaiseSystemError 'SPTBadmUser_Update', 'Database Error', @ErrorMessage
-- Emit the record we just inserted and return the return value
select * from UFTBadmUser##PK(null, @UserId)
return @ReturnValue
The update routine is slightly more complex than the insertion routine because the routine has to copy values out of the record being updated so as to be able to write them into the archive table. It also performs a test to see whether the record has changed, in order to minimize the amount of archiving (if there's been no change, why write another copy of it into the archive table?). But otherwise the code is very similar. The code in bold performs the actual update.
The deletion routine is similar to the insertion routine except that of course it deletes records instead of inserting them. Since only the primary key is needed to identify the record to be deleted, the only non-administrative parameter is the primary key. Here is the code for the deletion of a record from TBadmUser:
-- **** AUTO-GENERATED 'DELETE' STORED PROCEDURE FOR 'TBadmUser' ****
if not object_id('SPTBadmUser_Delete','P') is null drop procedure SPTBadmUser_Delete
go
create procedure SPTBadmUser_Delete
-- declare parameters for the primary key and audit date and userid
@UserId bigint,
@AuditDate datetime,
@AuditUserId bigint,
@AuditDateNEW datetime
as
-- INITIALIZE
declare @ReturnValue int
select @ReturnValue = 0
declare @ErrorMessage varchar(max)
-- MAIN PROCEDURE BODY
begin try
-- declare a variable to hold most values from the record being deleted
declare
@_LoginName varchar(20),
@_Notes varchar(max),
@_AuditDate datetime
-- assign values from the record being deleted
select
@_LoginName = LoginName,
@_Notes = Notes,
@_AuditDate = AuditDate
from TBadmUser
where
UserId = @UserId
-- see if this record has been deleted or modified since being acquired
exec SPutlCheckOptimisticConcurrency @_AuditDate, @AuditDate, 'SPTBadmUser_Delete'
-- set archive status
declare
@AuditStatus char(1)
select @AuditStatus = 'D'
-- delete & archive the record
delete from TBadmUser
output
@UserId,
@_LoginName,
@_Notes,
@AuditDateNEW,
@AuditUserId,
@AuditStatus
into TBadmUser#
where
UserId = @UserId
end try
begin catch
select @ErrorMessage = error_message()
select @ReturnValue = -1
end catch
-- TERMINATE
if @ReturnValue < 0
exec SPutlRaiseSystemError 'SPTBadmUser_Delete', 'Database Error', @ErrorMessage
return @ReturnValue
The deletion routine is slightly more complex than the insertion routine because the routine has to copy values out of the record being deleted so as to be able to write them into the archive table. But otherwise the code is very similar. The code in bold performs the actual deletion.
One of the ways that RAP makes systematic design palatable is that it provides short-term rewards in return for desirable long-term behaviors. For example, ideally programmers should always:
As trivial as these might seem, it is the rare project in which these tasks are performed rigorously. The primary reason is that programmers are generally not rewarded for exhibiting these behaviors. Another is that in the short term, programmers may actually be punished for doing these things. For example, if a programmer defines a foreign key and then writes code that violates the relationship, the easiest way to alleviate the problem and make one's schedule is to simply remove the foreign key.
To reverse this unfortunate psychology, RAP rewards programmers immediately for good behavior. When a programmer creates any of the above objects, RAP rewards him/her by auto-generating lookup routines that alleviate the programmer's need to write such routines. Eventually the programmer comes to realize that the fastest way to get an application written is to exhaustively define keys and indexes, ensuring that all key-and-index based lookups that the programmer might want in the future are already written.
The database generator generates four "fetch" user functions for table TBadmUser. Two of these (the PK ones) arise from the definition of the table's primary key, and the other two (the UK ones) arise from the definition of the unique index on the field "LoginName":
We generate user functions rather than stored procedures because user functions are far more reusable. The output of a table-valued user function can take the place of a table in any SQL query, so unlike with stored procedures we can combine as many user-function retrievals as we wish into queries of any desired complexity. Thus the query logic that RAP generates is not confined to simply piping data back to the application. We could, for example, use these user functions to build a view or stored procedure that drives a report. We will see shortly why this is useful.
You may have noticed that each user function has "@AsOfDate" as its first argument. Let's look at the code in one of these functions to see what that is about:
-- **** AUTO-GENERATED 'FETCH' USER FUNCTION FOR 'TBadmUser[PK_TBadmUser]' **** create function UFTBadmUser##PK ( -- declare the 'As Of' parameter @AsOf datetime, -- declare other parameters @UserId bigint ) -- declare the return value returns @ReturnValue table ( UserId bigint, LoginName varchar(20), Notes varchar(max), AuditDate datetime, AuditUserId bigint, AuditStatus char(1) ) as begin if @AsOf is null begin insert into @ReturnValue select UserId, LoginName, Notes, AuditDate, AuditUserId, AuditStatus from TBadmUser where -- match every index field to its corresponding parameter UserId = @UserId end else begin insert into @ReturnValue select A.UserId, A.LoginName, A.Notes, A.AuditDate, A.AuditUserId, A.AuditStatus from TBadmUser# A where -- match every index field to its corresponding parameter A.UserId = @UserId -- don't emit records marked 'deleted' and A.AuditStatus <> 'D' -- require the most recent version preceding the 'As Of' date and A.AuditDate = ( select max(AuditDate) from TBadmUser# where -- match the primary keys UserId = A.UserId -- choose only records at or before the specified AsOfDate and AuditDate <= @AsOf ) end return end
The function looks to see whether you have passed a value of null for @AsOfDate. If so, then it simply retrieves the record matching the specified @UserId from the primary table (TBadmUser).
The interesting part is where you pass an actual date in @AsOfDate. In that case, the "else" query (above) executes. This query gets its data from the archive table (TBadmUser#). The logic in the "where" clause simply says, "get the record that matches the @UserId and whose AuditDate is the most recent date that precedes or equals @AsOfDate".
So ... you have a set of fetch routines which, if all passed the same @AsOfDate, will return records from archive tables representing the data that was in place "as of" that date. You can do this for every table in the application and you can build queries of any complexity from these routines. So in other words, you can build your own user functions or stored procedures that accept an @AsOfDate, construct your queries using these routines instead of table names, and such routines will return the data that was stored in your application as of the @AsOfDate.
Or to put it another way, both your RAP application and any procedures you write using these functions can retrieve data "as of" any given date. This is how the RAP sample application lets you see data "as of" the date you optionally specify at login time.
The routines that RAP generates are sufficient to provide you application with all the basic CRUD information needed to drive the app. However if you need to write queries that perform custom searches, or if your app will generate reports, then you will have to write some amount of custom code to support these features.
When creating a stored procedure to drive a report, typically you'd write a query that does some number of joins on tables, like this one:
create procedure Report_PersonsAndNames as select P.GovtIdNumber, N.First, N.Middle, N.Last from TBcrmPerson P join TBcrmPersonName N on N.PersonId = P.PersonId
This procedure joins two tables containing data on persons and their names (in the RAP example, persons may have multiple names, e.g. maiden name, current name, etc.). The procedure above would produce a report capable of displaying only current data in your app's primary tables.
However in a RAP application you'd code this procedure this way, using the supplied fetch routines rather than direct references to primary table names:
create procedure Report_PersonsAndNames
@AsOfDate datetime
as
select
P.GovtIdNumber,
N.First,
N.Middle,
N.Last
from dbo.UFTBcrmPerson#PK(@AsOfDate, null) P
join dbo.UFTBcrmPersonName#PK(@AsOfDate, null) N on
N.PersonId = P.PersonId
Note that we've added a parameter to the stored procedure, namely @AsOfDate. We've made the following substitutions:
Note also that the @AsOfDate passed to the stored procedure is passed on to each fetch routine. Each fetch routine is also called with a null second argument, indicating that all records from the table should be returned (we could filter the output by passing a second procedure parameter to one or more of the fetch routines, but let's keep it simple). The effect of this procedure is to produce a complete report "as of" the passed-in date. If you pass an @AsOfDate of null, then the fetch routines retrieve current data from their corresponding primary tables. If you pass an actual date, then the fetch routines retrieve data from their corresponding archive tables as of the @AsOfDate.
What this means is that you can produce a report of any desired complexity whose data is "as of" any specified date. So in addition to the fact that your RAP application can retrieve application data "as of" any given date, you can also construct reports and other custom data-driven objects that can perform in the same way that the core application does, by simply having the application pass your objects the desired "as of" date.
The Database Generator also generates stored procedures whose behaviors are identical to the user functions above:
These are the routines that your RAP application will make available for your application's use in querying the database. Note that you don't have to write a line of this by hand. And in fact if you don't need to write any specialized queries, you don't even have to know how these routines work.
One of the big pains in writing an application is writing the data layer. In the early days of Microsoft's development tools (DAO, ADO) Microsoft provided really primitive application-side structures to assist programmers in temporarily storing database info within the app, and programmers generally did a really miserable job of managing the database/application interface.
With ADO.NET Microsoft continued improving the app-side data structures by introducing the DataTable, which allowed programmers to essentially represent the structure and behaviors of an entire table within the memory of an application. Of course the DataTable can still be used to create a truly awful application/database interface, which is why RAP contains an Object Relational Mapper (ORM) to manage all this. All you have to do is supply the RAP ORM with a set of DataTables corresponding to the tables in the database, along with some relationship information, and the RAP ORM will do all the database / application interfacing for you.
RAP's Database Generator can generate application code for either VB or C# applications. We'll show the C# version of the DataTable representing table TBadmUser (this may look like a lot of code but it's very regular):
// Code generated by ProjectPro RAP DBGenerator.
using SD = System.Data;
using ProjectPro.RAP.DLMapper;
namespace DataTables
{
public class TBadmUser: AbstractTable
{
#region "Constants"
// Table name
public const string TABLE_NAME = "TBadmUser";
// Column names
public class ColumnNames
{
public const string @UserId = "UserId";
public const string @LoginName = "LoginName";
public const string @Notes = "Notes";
public const string @AuditDate = "AuditDate";
public const string @AuditUserId = "AuditUserId";
public const string @AuditStatus = "AuditStatus";
}
#endregion
#region "Constructors"
public TBadmUser() : base(TABLE_NAME)
{
}
public TBadmUser(string description) : base(TABLE_NAME, description)
{
}
#endregion
#region "Column Definitions"
public class NamedColumns
{
internal SD.DataColumn _UserId;
internal SD.DataColumn _LoginName;
internal SD.DataColumn _Notes;
internal SD.DataColumn _AuditDate;
internal SD.DataColumn _AuditUserId;
internal SD.DataColumn _AuditStatus;
public SD.DataColumn @UserId
{
[System.Diagnostics.DebuggerHidden()]
get
{
return _UserId;
}
}
public SD.DataColumn @LoginName
{
[System.Diagnostics.DebuggerHidden()]
get
{
return _LoginName;
}
}
public SD.DataColumn @Notes
{
[System.Diagnostics.DebuggerHidden()]
get
{
return _Notes;
}
}
public SD.DataColumn @AuditDate
{
[System.Diagnostics.DebuggerHidden()]
get
{
return _AuditDate;
}
}
public SD.DataColumn @AuditUserId
{
[System.Diagnostics.DebuggerHidden()]
get
{
return _AuditUserId;
}
}
public SD.DataColumn @AuditStatus
{
[System.Diagnostics.DebuggerHidden()]
get
{
return _AuditStatus;
}
}
}
#endregion
#region "Initializer Functions"
private NamedColumns _NamedColumns;
public override void BuildColumns()
{
_NamedColumns = new NamedColumns();
_NamedColumns._UserId = CreateStandardColumn(TBadmUser.ColumnNames.@UserId, true);
Columns.Add(_NamedColumns._UserId);
PrimaryKey = new SD.DataColumn[] {_NamedColumns._UserId};
_NamedColumns._LoginName = new SD.DataColumn(TBadmUser.ColumnNames.@LoginName, typeof(System.String));
_NamedColumns._LoginName.MaxLength = 20;
Columns.Add(_NamedColumns._LoginName);
_NamedColumns._Notes = new SD.DataColumn(TBadmUser.ColumnNames.@Notes, typeof(System.String));
Columns.Add(_NamedColumns._Notes);
_NamedColumns._AuditDate = CreateStandardColumn(TBadmUser.ColumnNames.@AuditDate, false);
Columns.Add(_NamedColumns._AuditDate);
_NamedColumns._AuditUserId = CreateStandardColumn(TBadmUser.ColumnNames.@AuditUserId, false);
Columns.Add(_NamedColumns._AuditUserId);
_NamedColumns._AuditStatus = CreateStandardColumn(TBadmUser.ColumnNames.@AuditStatus, false);
Columns.Add(_NamedColumns._AuditStatus);
}
#endregion
}
}
Here are the only details you really need to know about the tables (such as the one above) that RAP generates for you:
That's almost all there is to building your data layer (there's a bit more below). When accessing tables from within your business rules layer, use the following guidelines:
The RAP-generated tables automatically create all the stuff you need to properly access tables and their components.
This section contains everything you will need to know about the RAP ORM, so if it seems a bit long, compare it to the multi-hundred-page instruction manuals that accompany most other ORMs.
In order for the RAP ORM to properly process tables, it must understand their relationships. With this knowledge, the RAP ORM can do things like automatically simulate cascading deletions in memory prior to trying to implement database deletions ... and it can give you and your application users options that would simply be impossible if we waited for the database to cascade things for us.
In addition to the table definitions that the Database Generator creates for you, you need to create one more class, named TableManager, in the data layer. Use the TableManager in the example. The TableManager instantiates tables on an as-needed basis. The version in the sample application of course contains tables that are appropriate to the sample. You will need to replace these with yours.
The TableManager is a class with a bunch of properties corresponding to the names of the tables in your app's database. It also has a property called "Members" (which you could call something else) that lists all the properties (i.e. tables). When you request a table from the TableManager (by calling on the appropriate property), the manager looks to see if the table has already been instantiated. If not, the TableManager instantiates it.
You do not have to write this instantiation code, because the RAP Database Generator creates it for you. All you have to do is assemble all the properties into a single class, in the manner of the example program. Here is the code that is generated for a single table in the "ExampleCRM" sample program:
// Code generated by ProjectPro RAP DBGenerator.
// Table TBcrmPersonName
private DataTables.TBcrmPersonName _TBcrmPersonName = null;
public DataTables.TBcrmPersonName TBcrmPersonName
{
get
{
if( _TBcrmPersonName == null)
{
// Instantiate the table.
const string Description = DESCRIBE_ME;
_TBcrmPersonName = new DataTables.TBcrmPersonName(Description);
// Instantiate the table's foreign key relationships.
// TBcrmPersonName.PersonId => TBcrmPerson
RelationshipManager.AddRelationship(new Relationship(
TBcrmPerson,
_TBcrmPersonName,
DataTables.TBcrmPersonName.ColumnNames.PersonId,
String.Empty, String.Empty,
true,
Relationship.RemoveChild.YOUPICK,
Relationship.DeleteParent.YOUPICK));
return _TBcrmPersonName;
}
}
The above code has been slightly edited down for the sake of simplicity. There are two basic things happening here:
The Database Generator purposely generates non-compile-able tokens "DESCRIBE_ME" and "YOUPICK" (in red above) as indicators to the programmer of where some coding must be done. Let's start with the Description and DESCRIBE_ME.
When RAP generates error messages or informative messages regarding data that it is processing in tables, it wants to produce a human-readable description of the specific record involved. So instead of producing incomprehensible gibberish regarding primary keys or primary key values and such, RAP instead wants to deliver your user an English-language description of the data in any given record (in any given table).
In order for RAP to do this, you must supply each table with a formula for generating the description of any given record in that table. So each RAP table stores a description field containing that formula. A simple macro processor translates whatever string you put into DESCRIBE_ME string into a run-time description of a particular record, in the following fashion:
So to illustrate, let's look at a simplified version of the DESCRIBE_ME string that we substituted for this table in our ExampleCRM application:
const string Description = "person name '[First] [Middle] [Last]'";
When generating a description for a particular record in this table, the RAP macro processor will substitute the values of the fields "First", "Middle", and "Last" in the appropriate places and generate a run-time description like person name 'John Q. Doe'. Now let's extend our Description:
const string Description = "person name [First] [Middle] [Last] of {PersonId}";
What we've added here is a foreign key reference. This tells the macro processor that the current table contains a field named PersonId. Via the relationships described in this very section, RAP knows that PersonId refers to the primary key of a table named TBcrmPerson. At run time the macro processor generates all the parts of the Description that it can without following any foreign keys. Then for each foreign key it calls itself recursively, generating the Description of whatever record the foreign key is referencing, and substituting that into the Description of the current record. So in this case let's look at the the Description of a record in TBcrmPerson:
const string Description = "person '[GovtIdNumber]'";
Table TBcrmPerson represents persons, who have one or more names that are stored in the TBcrmPersonName table. In TBcrmPerson there is no stored name by which to identify a person. Instead a reasonable field that can be used as an informal business key is the person's government ID number (e.g. Social Security number in the U.S.). Thus the Description of a given person might look like person '111-11-1111'.
So when generating the Description of PersonName "John Q Doe", which is one of the names for the Person having SS# 111-11-1111, the macro processor goes through the following logic.
So when designing Descriptions one must adopt a recursive mindset, understanding that each Description in each parent table will end up being embedded in the Descriptions of children.
Within each table instantiation routine is some generated code that defines its relationships to each of its parents. In the case of TBcrmPersonName, for example, there is a parent table named TBcrmPerson. The definition that corresponds to this relationship is the second piece of bold code in the code sample above. The piece of code illustrated here is a call to a routine called AddRelationship that causes the TableManager to add the relationship to its set of relationship definitions.
The RAP Database Generator generates all the code needed to represent every relationship in the database, except that it does not know two things:
Since these are both judgment calls that have to do with the business rules of the application, RAP cannot possibly be smart enough to make these decisions. So it inserts the YOUPICK tokens for you to replace.
RAP offers five options for cascading the deletion of a parent down to the children
RAP provides an enumeration called Relationship.RemoveChild that contains the above possibilities and which can be used to replace the YOUPICK token.
Now you may wonder about options 2 and 4, which imply that the data layer (which has no UI and does not communicate directly with the user) could possibly ask the user for permission to delete or nullify children. The answer is that it does so indirectly, via an event that it fires. As the RAP ORM performs cascading deletions, it checks the relationship statuses for all relatives of the record being deleted, and whenever it encounters one of these it fires and event that is presumed to be handled by the Business Rules and UI. These agents (Business Rules and UI) are responsible for presenting the user with information about what is being automatically deleted (using descriptions provided by the Description mechanism described above). They are also responsible for collecting the user's response (yes or no) and passing that response back when servicing the event. Thus your RAP application has a highly unusual feature ... it can notify users of attempts to indirectly delete records (as a consequence of cascading deletions) and give the user an intelligently worded option to say yea or nay.
RAP offers these options for cascading the deletion of the last child up to the parent:
RAP provides an enumeration called Relationship.DeleteParent that contains the above possibilities and which can be used to replace the YOUPICK token.
In order to complete the data layer, you need to:
When you are done you will have done something that is rarely accomplished in the world of application development: you will have fully and unambiguously described all the data and relationships that your application could possibly need to manipulate, both now and in the future.
Unlike the layers below it, the RAP Business Rules Layer is not auto-generated. Instead, it contains templates for constructing RAP Views, which are designed to support user interface components. The RAP BRBase project contains some items that facilitate construction of consistent business layers that encode all business logic (thereby removing it from the UI, where many programmers put it) and that have consistent structure from application to application.
There are potentially many functions that a business rules layer can perform, but for our purposes we'll divide it into two parts:
At this point RAP provides support only for user interface CRUD. If you are familiar with architectural models, RAP basically implements the model-view-controller (MVC) model, in which:
The purpose of the MVC model (and the RAP business rules model) is to get all the business logic out of the user interface, so that you can put multiple UIs onto your application and all of them will behave identically (since all are controlled by the same "controller"). This is a far cry from the typical application implementation, where users (for lack of understanding, discipline, or time) simply stick all their business logic into the UI, making it non-reusable in other UIs. In an environment increasingly populated by devices requiring radically different and dedicated user interfaces (mobile phones, tables, laptops, desktops), it seems imperative that common logic drive all the user interfaces.
A RAP View is intended to control a complete user interface component, such as a web page, a Windows form, a mobile page, etc. Each such component typically displays:
The purpose of the CRUD portion of the UI is to display this data in a user-friendly manner, which does not necessarily resemble the way the data is stored in the database, and to allow the user to modify the data and store it back to the database. Each View may consist of data from various tables having various types of relationships. In order to support all these forms of data display, the RAP BRBase project contains the following:
The DataColumnList is simply a list of DataColumns. You use it to specify lists of computed columns that you want computed or otherwise manipulated.
The DataTableExtended is an extension of the standard DataTable. You use it to add computed columns to the data in a standard DataTable. The DataTableExtended keeps each row in the computed columns consistent with the original row data with which it is associated.
The DataView is an extension of the standard DataView object, with added properties, events, and overrides designed to make DataViews (views of single tables) more manageable in the RAP environment. At the highest level, we have the View object, which assembles all these aforementioned items in the following structure:
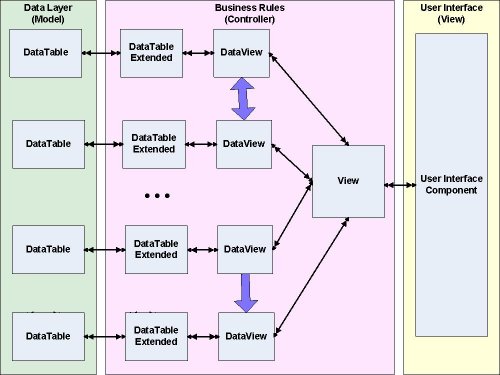
This structure allows for an extraordinary amount of flexibility in designing a data source for a user interface (which we call a "View"). The View gets its data from a collection of DataViews (which are RAP inheritors of the .NET DataView object). Each DataView has as its data source a DataTableExtended (which is a RAP extension of DataTable allowing for inclusion of computed columns). These in turn get their data from DataTables (actually RAP AbstractTables) in the data layer.
The purple arrows denote connections within the Business Rules. The DataViews are connected to each other via two types of relationships:
In the many-to-one (parent/child) relationship, it is presumed that the parent controls the display of the children, so that changing the parent changes the children being displayed. In the many-to-many relationship, the implementer designates one of the two peers as the master, and user's choice of the master element controls the selection of the peer's members.
It is beyond the scope of this paper to discuss the precise details of the Business Rules section; it is easier to simply look at the code in the ExampleCRM BRViews project. At this writing, the project contains one example of a many-to-one (Persons / Person Names) and two examples of peer-to-peer (Users / Groups) relationships.
The purpose of the Business Rule section is to provide well-controlled prototypes for designing data transformations that support user interfaces. The most important thing that the RAP Business Rules accomplish is to completely remove all business rules from the user interface (where they are not reusable) and centralize them into one project that can support multiple user interfaces consistently. As with everything else in RAP, the overall goal is to eliminate useless variation.
As we saw above, a primary objective of RAP is to minimize user interface content. Consequently there is not that much to say about the RAP UI. The primary idea here is that the user interface contains no business logic - that is, the little code that the UI contains is entirely in support of the UI controls and other objects.
The eventual idea is that RAP will contain a number of patterns from which implementers can select. The version available at this writing contains two basic patterns:
The user interface (UIWindows) project structure looks like this:
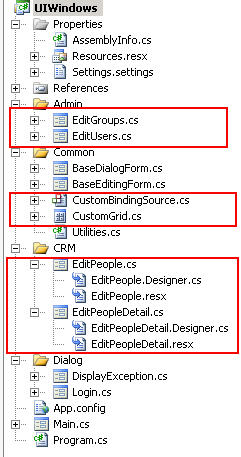
The primary objects of interest are highlighted. Let's start with the center group above. Generally speaking a UI will make use of grids and, where grids are not used, binding sources. The default .NET BindingSource is extremely limited in its customization capabilities (i.e. any attempt to use it in conjunction with almost anything but a standard .NET data source is extremely frustrating), so in the UI we provide a customized one called CustomBindingSource. If you implement any forms that use binding sources, use this one rather than the default .NET BindingSource.
The standard .NET DataGridView similarly has some limitations that are overcome by our CustomGrid, which is actually a user control that has an embedded DataGridView. We implement it as a UserControl (rather than just inheriting from a DataGridView) in order to add some useful buttons:
These two core UI objects (the CustomBindingSource and the CuistomGrid) make it possible to connect easily to RAP Views in the Business Rules layer.
Aside from these core reusable objects, everything else in the UI is extremely simple. There are two administrative screens. EditUsers is used to define Users and assign them to Groups:
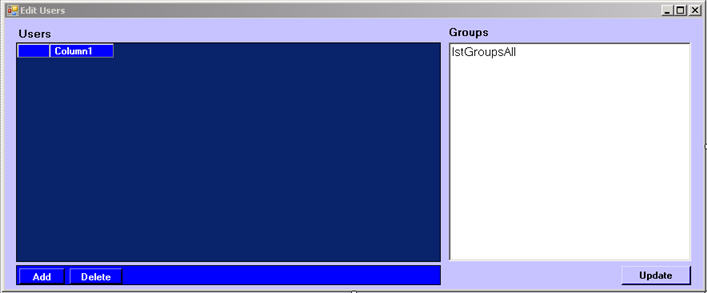
The paradigm here is that we use a grid to define Users, plus a list that shows all existing groups. In order to assign / deassign Users to/from Groups, the user selects or deselects Groups in the list.
The same paradigm is used to assign Groups to Users and Roles.
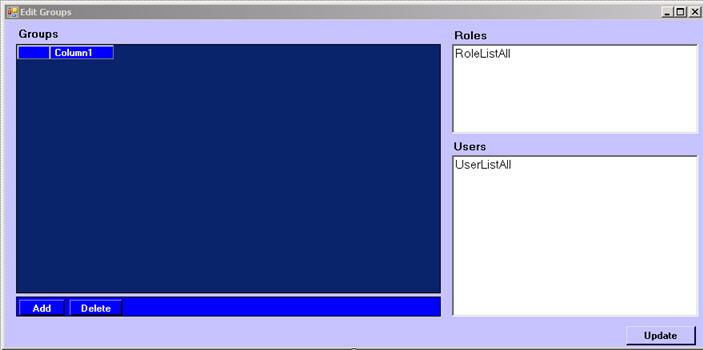
Here we're doing the same sort of thing except that we're defining Groups on this screen and assigning Users and Roles to them.
In both of these cases, Users, Groups and Roles are all peer-to-peer relationships. Each of these two screens is backed by its own View in the Business Rules. In the View supporting the Edit Users screen, Users are designated as the primary object and the list of assigned Groups changes according to which User is selected. In the View supporting the Edit Groups screen, Groups are designated as the primary object and the list of assigned Users and Roles changes to match the selected Group. Note that all of this code is written and all the work is done in the Business Rules, not the user interface.
RAP goes far beyond traditional notions of consistent design. A RAP application does all the following in the interest of eliminating useless, counterproductive variation in applications:
Each of these benefits alone would produce substantial savings for the typical software development, in terms of both reduced development time and reduced ongoing maintenance. Together, they provide an enormous cost reduction over today’s ad-hoc development methods.
When Henry Ford introduced the Model T in 1908, he built it using the standard one-at-a-time craftsman-style method that was prevalent at the time. Once he determined that he had a showroom winner, he turned his attention to manufacturing it consistently and therefore efficiently. When he started his assembly line in 1913, the Model T cost about $16,000 in 2008 dollars. After ten years, the Model T was selling for about $4,000 in 2008 dollars – a 75% cost reduction. And its standardization made possible other economies, both in Model-T maintenance and in other aspects of our society, that were formerly unimaginable.
RAP is a first step in automating software application development. In its present form it will probably save the typical development team about 25% in initial development and ongoing maintenance costs. Tomorrow, perhaps, we can approach the efficiency improvement of the automotive assembly line. Certainly, it seems, it would be pretty silly not to try.